

SketchSause
Abstract
Abstract
Join the meet to see the "sause": https://meet.google.com/bsz-jitc-cwr
Aim
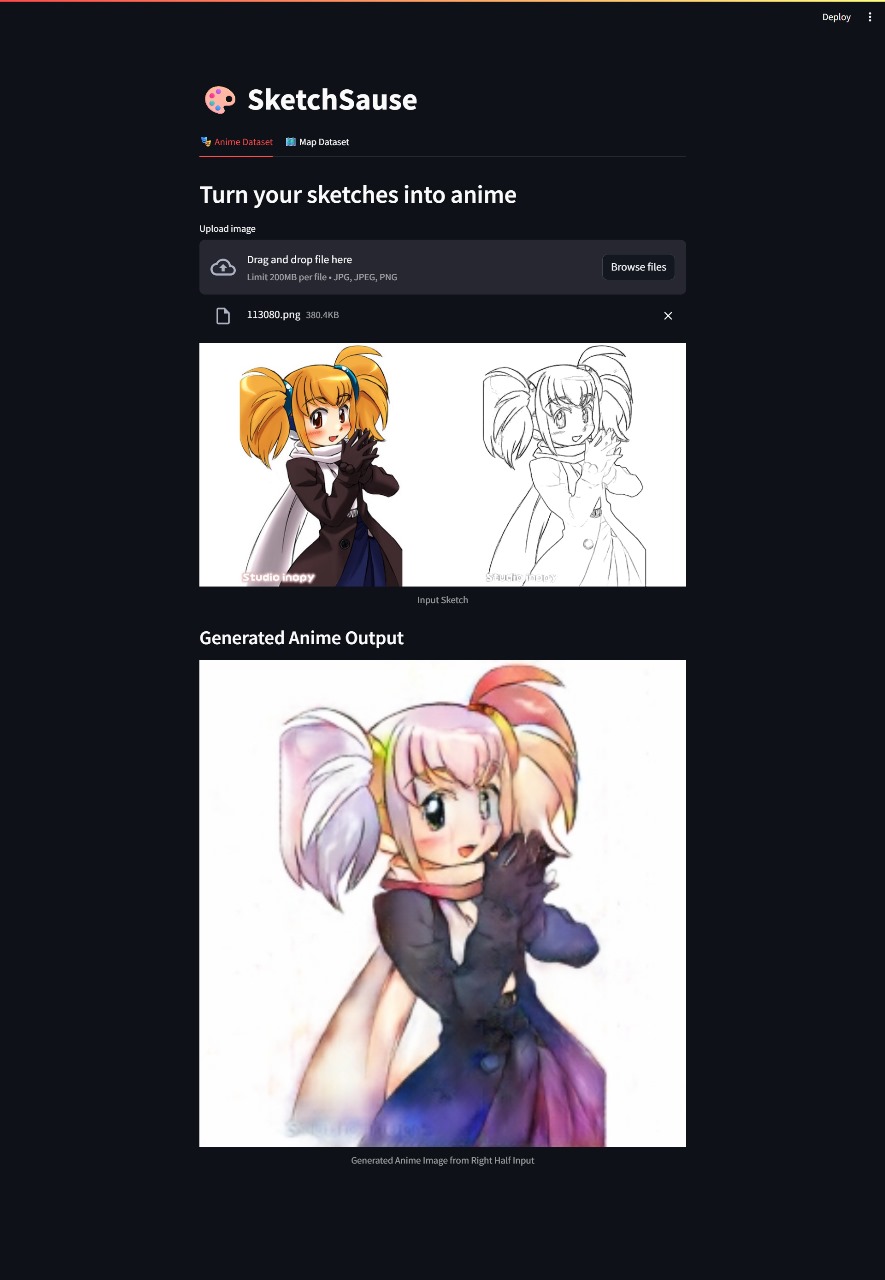
This project presents a gafheneral approach for image-to-image translation using conditional adversarial networks. Instead of designing a different solution for each task, this approach enables the model to learn both the mapping from input to output images and the loss function itself. By applying the same U-net architecture across tasks, in this case: image translation between aerial images to maps(using the maps dataset), and creating a colorized image from edges(using the anime dataset).This general solution simplifies the development process and broadens the applicability of image translation models.
Introduction
With recent developments in deep learning, a powerful new approach has emerged: using conditional adversarial networks (cGANs) to guide image-to-image translation. This project explores a unified framework designed specifically to handle diverse image transformation tasks like colorizing anime sketches and converting aerial photographs into map-style renderings.
Image-to-image translation focuses on converting an input image into a corresponding target image while maintaining essential visual structure. Traditional methods often rely on custom architectures and manually designed loss functions tailored to individual tasks—whether it’s colorization, segmentation, or style adaptation—making them difficult to generalize and scale. Our approach addresses this challenge by applying a single, general-purpose solution inspired by how humans can intuitively imagine a colored anime scene from a black-and-white sketch or visualize a map from an overhead view.
We present a framework based on conditional Generative Adversarial Networks (cGANs) that learns both the mapping from input to output and the loss function required to guide this transformation. This dual learning capability removes the need for handcrafted loss functions, enabling broader applicability across different tasks with minimal changes to the architecture.
The system architecture combines:
A U-Net-based generator, which ensures preservation of fine details—crucial for intricate anime line art and precise geographical features in aerial imagery.
A PatchGAN discriminator, which evaluates local patches of the image for realism, encouraging the network to generate sharp and coherent outputs.
This configuration enables the model to generate vivid, detailed anime-style colorizations from monochrome sketches and accurate, clean map-style outputs from aerial photos—all using the same network architecture.
Through experiments on datasets of anime sketches and aerial-map image pairs, our results show that this unified cGAN framework performs comparably or better than task-specific models. It proves especially effective at maintaining structural accuracy while producing visually appealing results.
Key contributions of this project include:
- A unified framework for diverse image translation tasks, specifically anime sketch colorization and aerial-to-map generation.
- A robust architecture combining U-Net generators with PatchGAN discriminators to enhance output sharpness and detail retention.
- Elimination of task-specific loss engineering through learned translation and evaluation.
- Strong performance across distinct domains using a single architecture.
Literature Survey and Technologies Used
1. Literature Survey
The field of image-to-image translation has seen rapid progress with the advent of Generative Adversarial Networks (GANs). A key milestone in this domain is the Pix2Pix model, introduced by Isola et al. (2017) in their paper “Image-to-Image Translation with Conditional Adversarial Networks.” Pix2Pix is designed for supervised learning tasks where paired input-output images are available.
Pix2Pix leverages a conditional GAN (cGAN) framework:
- The generator (G) learns to translate an input image into an output image.
- The discriminator (D) tries to distinguish between real output images and those generated by G, given the same input.
The objective combines:
- Adversarial Loss – Ensures realism in generated images.
- L1 Loss – Encourages similarity to the target image at the pixel level, preserving structure.
- Pix2Pix has been successfully applied to various tasks:
- Semantic labels → Photos
- Aerial images ↔ Maps
- Black & white → Color
- Sketches → Colored images
In our project, we explored two applications of Pix2Pix: Anime Sketch Colorization and Satellite to Map Translation.
A. Anime Sketch Colorization
This task converts grayscale anime sketches into colored images, requiring the model to infer plausible styles and colors.
Challenges:
- High variability in styles
- Sparse input details
We used cGAN-based Pix2Pix, which learns structural and style mappings from paired sketch-color data, enabling creative yet consistent outputs.
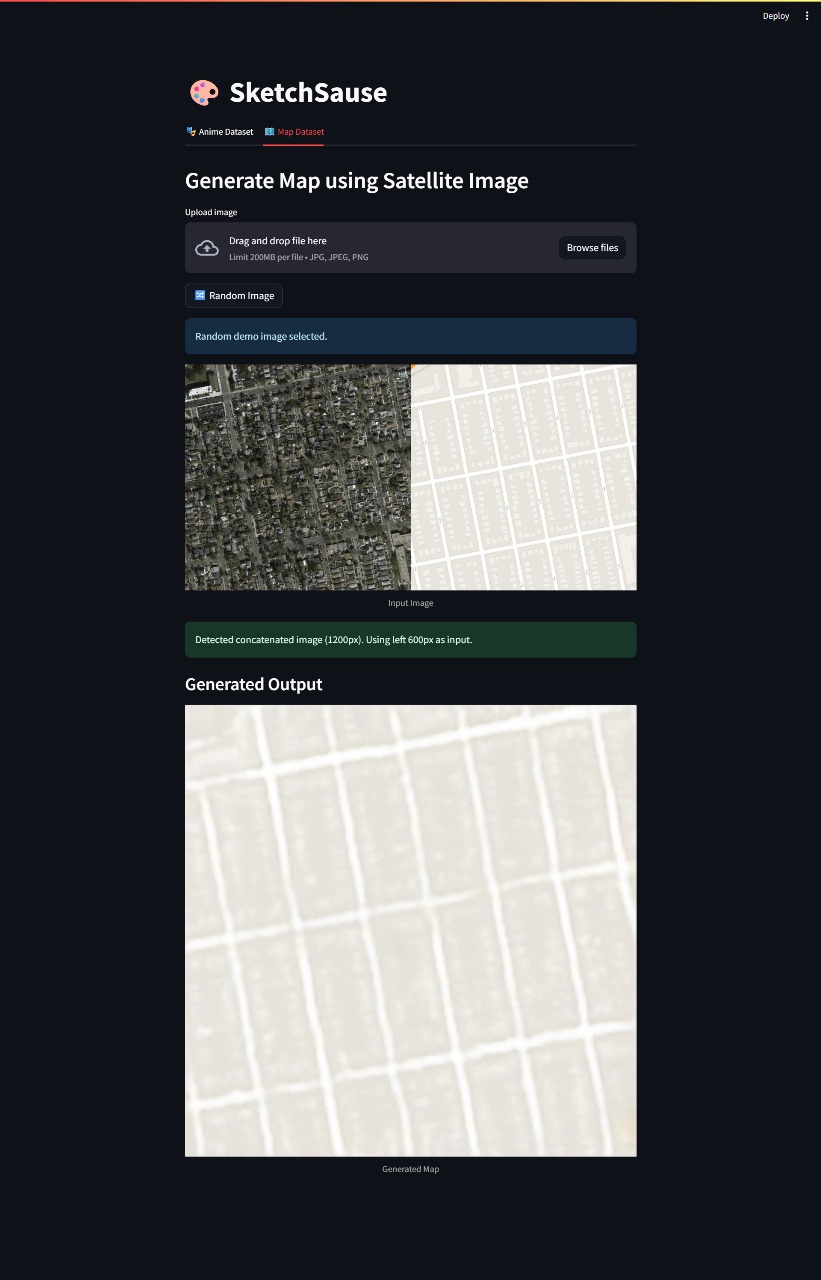
B. Satellite to Map Translation
This task converts satellite images into structured map views, requiring spatial precision.
Challenges:
- Preserving geometric alignment.
- Translating textures into clean map features.
We used WGAN-GP instead of cGAN for improved stability and structure. Combined with L1 loss, it helped maintain spatial accuracy and realism.
2. Technologies Used
Libraries and Frameworks
- PyTorch: For building and training the Pix2Pix model.
- Torchvision: Used for image transformations and utilities.
- NumPy & PIL: For image preprocessing and manipulation.
- Matplotlib: For visualizing outputs and training performance.
- tqdm: For monitoring training progress.
Model Architecture
- Generator: A U-Net architecture with skip connections to preserve low-level information from the input.
- Discriminator: A PatchGAN classifier that penalizes structure at the scale of image patches (e.g., 70×70), focusing on local realism.
Training Configuration
Loss Functions
- Anime Dataset (cGAN):
- Adversarial Loss (cGAN-based): Encourages the generator to produce realistic colored anime images.
- L1 Loss: Promotes structural similarity between the output and target image.
- λ (lambda): Set to 100 to strongly enforce pixel-level similarity, due to the ambiguous nature of anime colorization.
- Map Dataset (WGAN-GP):
- Wasserstein Loss with Gradient Penalty (WGAN-GP): Provides more stable training and better convergence for structured tasks like satellite-to-map translation.
- L1 Loss: Helps maintain spatial consistency and alignment.
- λ (lambda): Set to 10 to balance realism and pixel-wise accuracy.
Optimizer
- Adam Optimizer used in both cases.
- Anime Dataset: Learning Rate = 2e-4, β1 = 0.5, β2 = 0.999
- Map Dataset: Learning Rate = 1e-4, β1 = 0.0, β2 = 0.9
Methodology
Problem Statement
Specifically, we focus on:
· Converting anime sketches into colored illustrations
· Translating between paired domains (e.g., maps ↔ aerial photos)
Our goal is to develop a robust implementation capable of generating high-quality translated images while preserving structural consistency with the input images.
Datasets Used
We utilized two comprehensive datasets:
Anime Sketch Colorization Pair Dataset

- Source: Kaggle (anime_dataset)
- Size: 14,224 paired images (sketch and colored versions)
- Resolution: Original 512×512 pixels
- Purpose: Training the model to colorize anime line art sketches
Original Pix2Pix Dataset Collection
- Source: Kaggle (Pix2Pix Dataset)

Subsets:
- maps: 1,096 aerial photograph ↔ map pairs (used in our implementation)
- facades: 400 architectural labels ↔ building facades
- cityscapes: 2,975 semantic labels ↔ street scenes
- edges2shoes: 50,025 shoe edge ↔ photo pairs
- edges2handbags: 137,000 handbag edge ↔ photo pairs
Purpose: Training the model for diverse image translation tasks
All images were resized to 256×256 pixels for uniformity. The data was split into 80% training, 10% validation, and 10% testing sets.
Network Architecture
The Pix2Pix architecture consists of two main components:
Generator Network
We implemented a modified U-Net architecture with the following specifications:
· Encoder: 8 down-sampling blocks with Conv2D layers (kernel size 4, stride 2), Leaky ReLU (slope = 0.2), and batch normalization (except for the first block). Channel progression: 3→64→128→256→512→512→512→512
· Decoder: 8 up-sampling blocks with ConvTranspose2D layers (kernel size 4, stride 2), ReLU activations, dropout (rate = 0.5) in the first three blocks, and skip connections. Channel progression: 512→1024→1024→1024→1024→512→256→128→3
Discriminator Network
We used a PatchGAN discriminator:
· 5 convolutional layers (kernel size 4)
· First layer: stride 2, no normalization
· Middle layers: stride 2 with batch normalization
· Final layer: stride 1, outputs a patch of predictions
· Leaky ReLU activations (slope = 0.2)
· Channel progression: 6→64→128→256→512→1
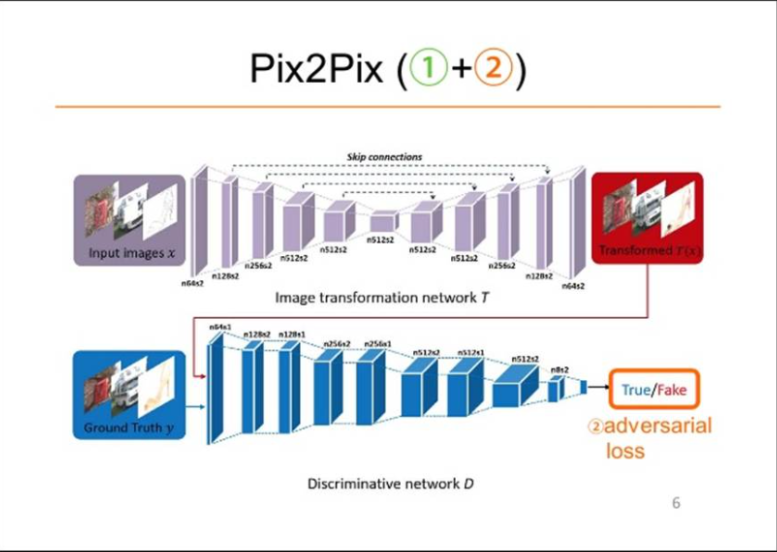
Loss Functions
A. Anime Dataset
· Adversarial Loss (cGAN): Encourages realistic output
· L1 Loss (Pixel-wise): Ensures structural similarity
Formula:
· L_cGAN(G, D) = E[log D(x, y)] + E[log(1 - D(x, G(x)))]
· L1(G) = E[||y - G(x)||₁]
· Total Loss: L_total = L_cGAN + λ · L1 (where λ = 100)
B. Map Dataset
· Generator Loss: Combines BCE (adversarial) and scaled MAE (L1)
· Discriminator Loss: Wasserstein loss with Gradient Penalty
Formula:
· L_D = -(E[D(x, y)] - E[D(x, ŷ)]) + λ_gp · GP
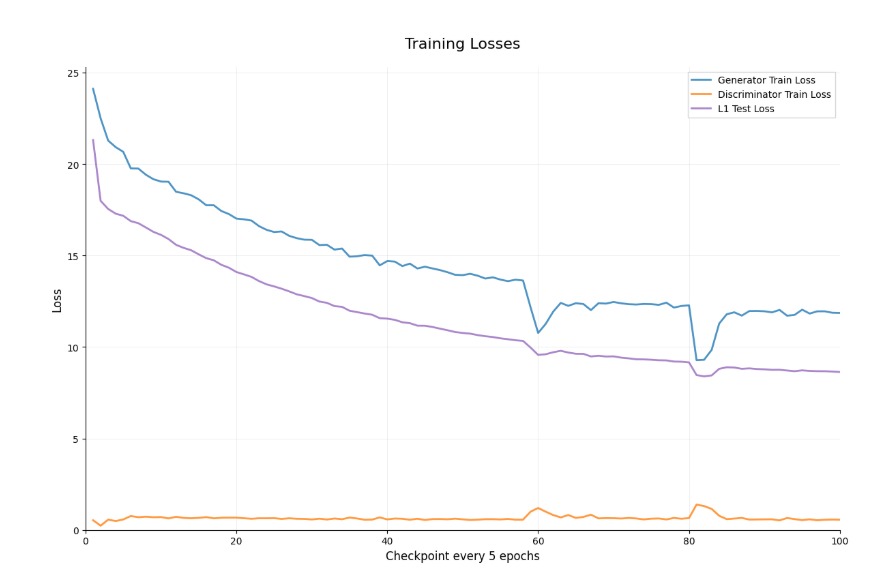
Training Procedure
A. Anime Dataset
· Resize to 256×256 pixels and normalize to [-1, 1]
· Domain-specific preprocessing (clean line art extraction)
· Data augmentation: jittering, random cropping, and horizontal flipping
· Optimizer: Adam (lr = 0.0002, β₁ = 0.5, β₂ = 0.999)
· Batch size: 1
· Epochs: 100 (50 constant lr, 50 linear decay)
· Alternate updates between discriminator and generator
B. Map Dataset
· Same preprocessing and augmentation
· Optimizer: Adam (lr = 1e-4, betas = (0.0, 0.9))
· Batch size: 32, epochs: 200
· Discriminator update frequency: 3 per generator update
· Validation at each epoch, sample saving every 25 epochs
Evaluation Metrics
Quantitative:
- Fréchet Inception Distance (FID)
- Anime: 30.878845053390958
- Maps: FID: 286.07
- Structural Similarity Index (SSIM)
- Anime Average SSIM over test set: 0.7639
- Maps: Avg SSIM: 0.7383
- Peak Signal-to-Noise Ratio (PSNR)
- Anime: Average PSNR on test set: 13.40 dB
- Maps: Avg Gram Matrix Distance: 0.000185
- Avg Gram Matrix Distance (Maps): 0.000185
Qualitative:
· A/B testing with original Pix2Pix
· Criteria: realism, input fidelity, aesthetic quality
Technical Challenges and Solutions
· Training Instability: Used spectral normalization and adaptive learning rate schedules
· Color Inconsistency in Anime: Integrated attention mechanisms
· Loss of Detail in Maps: Introduced feature fusion in skip connections
· Domain Generalization: Added adaptive instance normalization and domain-specific loss weighting
· Memory Limitations: Applied gradient checkpointing, mixed precision, and distributed training
These strategies improved both the visual output and performance metrics
Results
Anime





This section presents qualitative results of the trained Pix2Pix model (Wasserstein GAN variant) on the satellite-to-map translation task. For each example, we show the input satellite image, the expected map output (ground truth), and the predicted map generated by the model.
Conclusions/Future Scope
Conclusion
In this project, we explored the capabilities of the Pix2Pix conditional GAN framework for two distinct image-to-image translation tasks: satellite-to-map translation using the Maps dataset, and anime sketch colorization. For the map translation task, we enhanced the original Pix2Pix model by incorporating a Wasserstein GAN (WGAN) loss function. This modification improved the training stability and resulted in sharper and more structurally accurate map outputs from satellite imagery.
In the second task, we applied the standard Pix2Pix architecture to colorize anime sketches. The model learned to translate line-art style sketches into fully colorized anime-style images. Despite the lack of shading or grayscale cues, the network was able to infer plausible color distributions and apply them consistently across different input sketches. This demonstrated the adaptability of the Pix2Pix framework to artistic and creative domains.
Through both tasks, our project showcased the versatility of image-to-image translation techniques and highlighted the impact of adversarial loss enhancements on output quality.
Future Scope
Several directions remain open for future improvement and expansion:
- Quantitative Metrics:
- Incorporating image quality metrics such as SSIM, PSNR, and FID would allow for a more objective assessment of model performance across both tasks.
- Incorporating image quality metrics such as SSIM, PSNR, and FID would allow for a more objective assessment of model performance across both tasks.
- Sketch-to-Color Fine-tuning:
- Further improving the sketch colorization model through perceptual loss or style-aware training could lead to more vibrant and stylistically consistent results.
- Further improving the sketch colorization model through perceptual loss or style-aware training could lead to more vibrant and stylistically consistent results.
- Unpaired Training Approaches:
- Exploring architectures like CycleGAN could enable sketch colorization or map translation even in the absence of perfectly aligned datasets.
- Exploring architectures like CycleGAN could enable sketch colorization or map translation even in the absence of perfectly aligned datasets.
- Interactive Color Hints:
- Introducing user-guided color hinting (e.g., scribbles or palette input) could enhance control and produce more personalized colorizations.
- Introducing user-guided color hinting (e.g., scribbles or palette input) could enhance control and produce more personalized colorizations.
- Attention Mechanisms:
- Adding attention layers could help the models focus on key areas (e.g., character features in sketches or roads in satellite images), improving detail and consistency.
- Deployment for Creative Tools:
- Optimizing models for deployment in mobile or web-based creative tools could open real-time applications, such as automated sketch colorization platforms for artists or rapid geospatial map generation tools.
References
- GANS :GANS
- Image to image translation : reference
- Image-to-Image Translation using Generative Adversarial Networks(GANs):Medium article
Repo link
Codes for the project can be found here
Mentors & Mentees Details
Mentors
- Akshat Bharara [Compsoc] : 231cs110
- Rudra Gandhi [Compsoc] : 231ec147
Mentees
- Abhishek Sulakhe : 241ai001
- Rushi Patel : 241it065
- Saivinathi Korukonda : 241ds025
- Skanda Prasanna Hebbar : 241ch047
- Vivek Kashyap : 241ai043
- Yahya Faisal : 241ch059
Report Information
Team Members
Team Members
Report Details
Created: May 18, 2025, 1:25 p.m.
Approved by: Vishal Kamath [CompSoc]
Approval date: May 25, 2025, 10:37 a.m.
Report Details
Created: May 18, 2025, 1:25 p.m.
Approved by: Vishal Kamath [CompSoc]
Approval date: May 25, 2025, 10:37 a.m.