

CaptchaCrackNet
Abstract
Abstract
Meeting link: meeting link
Github repository: https://github.com/falconakhil/CaptchaCrackNet
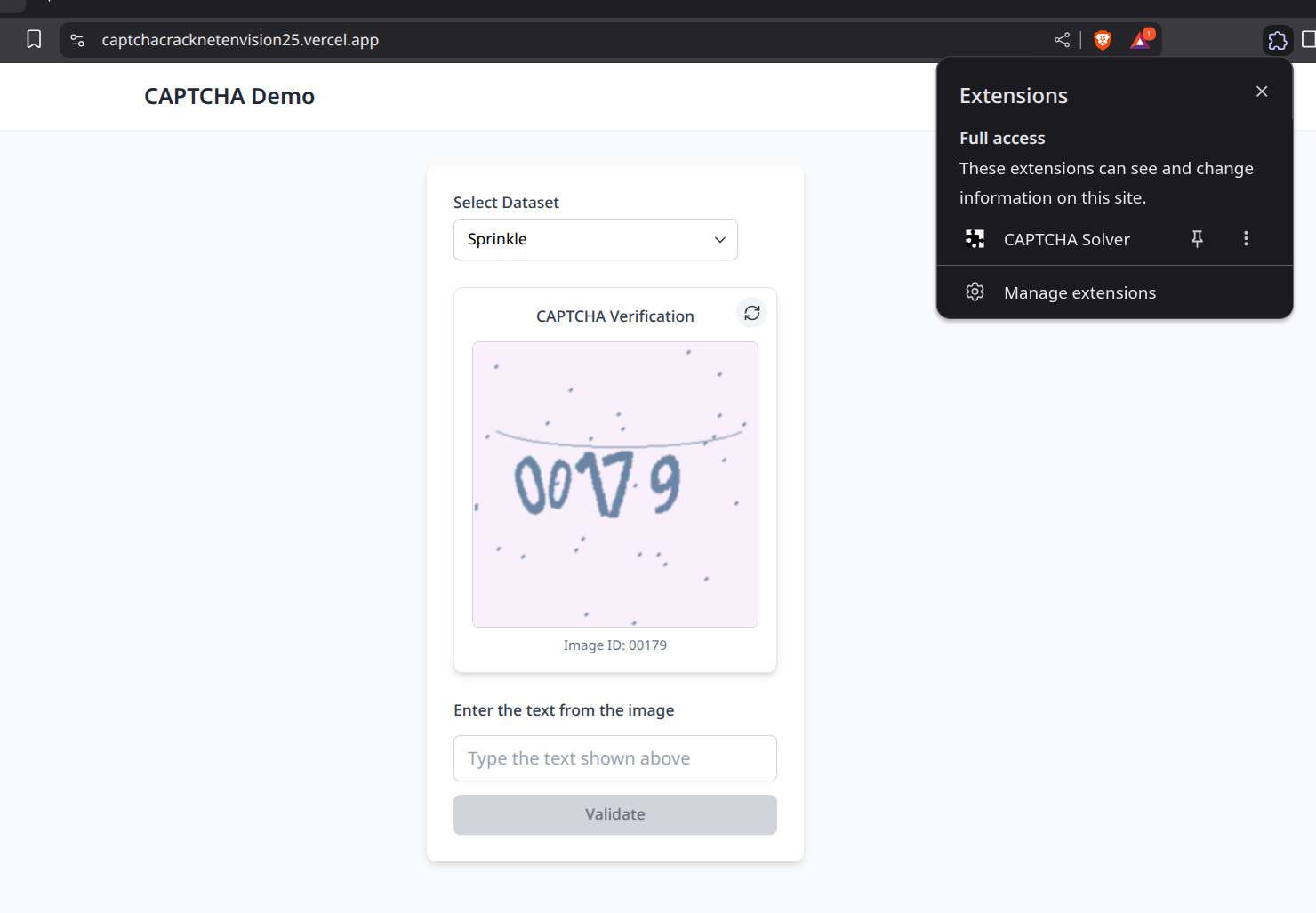
Demo website:https://captchacracknetenvision25.vercel.app/
Aim:
To use modern neural network architectures to bypass CAPTCHA systems, which are commonly used to distinguish humans from bots.
Introduction:
CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. It is a security mechanism designed to differentiate between human users and automated bots. CAPTCHA presents users with challenges that are easy for humans to solve but difficult for bots, such as identifying distorted letters.
CAPTCHAs are primarily used to:
- Prevent automated bots from accessing or abusing online services (e.g., spamming, brute-force attacks).
- Protect registration forms, login pages, e-commerce checkouts, and online polls from automated abuse.
- Reduce fraudulent account creation.
- Enhancing website security - by blocking suspicious or malicious bot traffic.
- Reducing fake reviews or ratings -Helps ensure that reviews or feedback come from real users, not automated systems trying to manipulate reputations.
CaptchCrackNet is a deep learning-based project designed to crack text-based CAPTCHAs. We present a CRNN model along with an extension to use it.
Literature review:
Adaptive CAPTCHA: A CRNN-Based Text CAPTCHA Solver with Adaptive Fusion Filter Networks
[1506.02025] Spatial Transformer Networks
[1312.6114] Auto-Encoding Variational Bayes
Technology used:
pytorch,torchvision,matplotlib
Methodology:
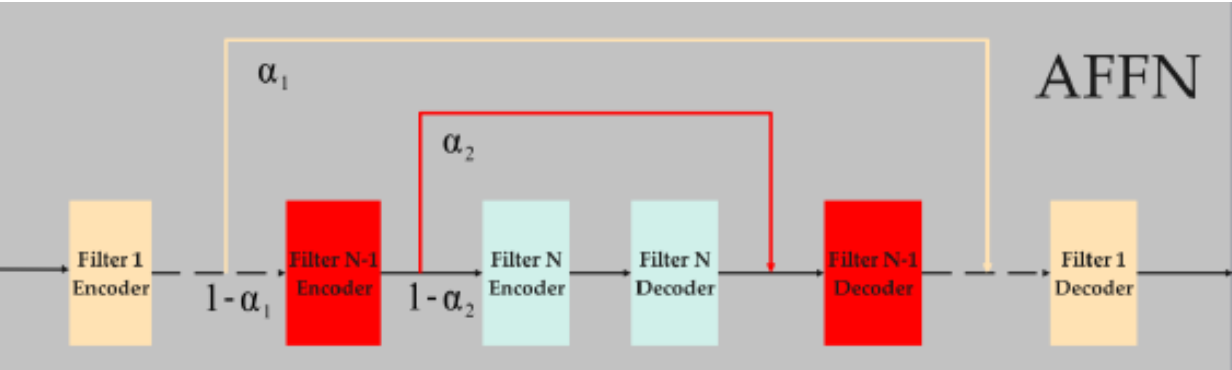
AFFN
To prevent web attacks, many artificially designed noise points and interference lines are added to the image, all in the same size with a width of 64 and a height of 192 pixels, thus requiring no scaling. However, grayscale processing of the images is necessary, which can greatly reduce the complexity of the model while maintaining the accuracy of CAPTCHA recognition. A robust filter network may help the subsequent CNN better extract features of CAPTCHAs, thereby improving recognition accuracy. In this study, AFFN is used for this purpose.
The number of layers depends on the noise in the dataset—the more noise, the larger the number of layers, and vice versa.By introducing the fusion factor Alpha in AFFN, adaptive filtering of noise can be achieved. The adaptive fusion factor controls the weights of the next nested filtering unit participating in the filtering.
CRNN
CRNNs Integrate two types of deep learning networks: CNNs& RNNs.
CNNs(Convulutional neural networks) are commonly used for ImageDetection. RNNs(Recurrent neural networks) is used here to understand the relationship b/w sequential characters in Captcha Images.
The CRNN used in this model features 2 convolutional Blocks, for feature extraction followed by a dropout layer which drops off 30% of the input data to prevent overfitting.
These patterns are flattened and transformed into a latent vector A single latent vector is then repeatedly fed into an LSTM, generating outputs for each character position sequentially.A fully connected layer maps LSTM outputs to class scores across a vocabulary (A–Z, a–z, 0–9).
The final result is a sequence of predictions, each representing a character in the CAPTCHA.
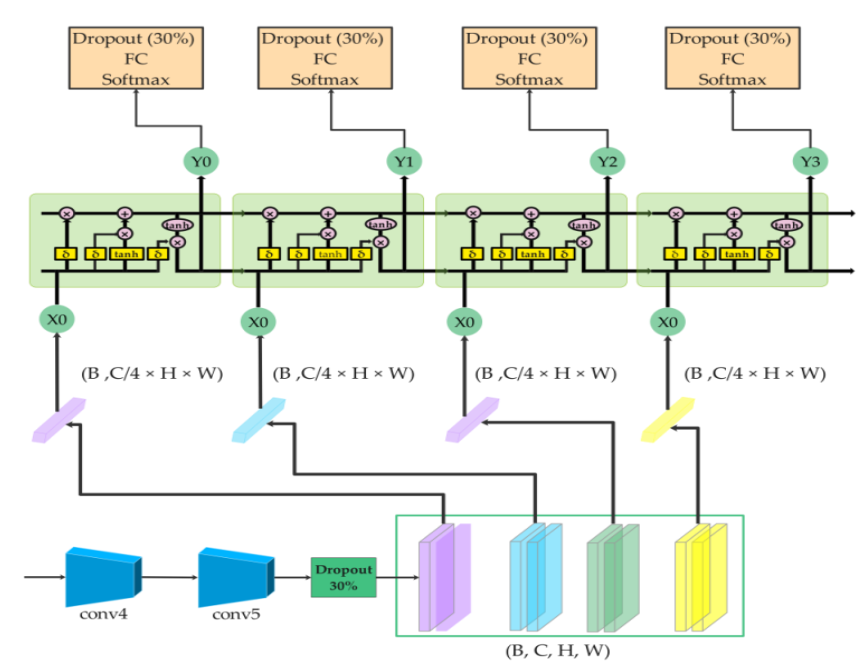
Figure Representing the working of a CRNN
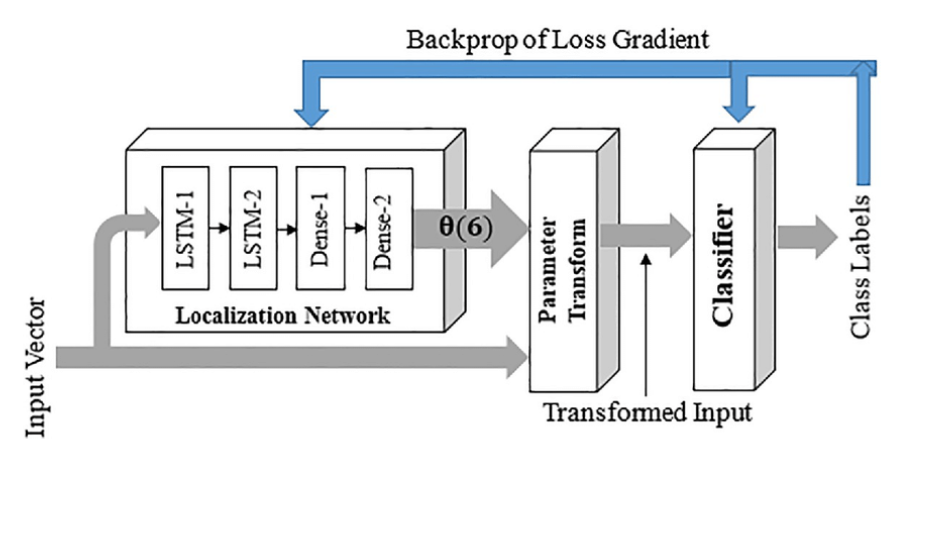
STN Implementation in CAPTCHA Model
Spatial Transformer Networks (STNs) are modules that enhance deep learning models by allowing them to actively spatially transform feature maps. In CAPTCHA recognition, where characters may be distorted, shifted, or rotated, STNs help normalize these irregularities before further processing.
Why Use STNs in CAPTCHA?
Robustness to Deformation: CAPTCHAs often have skewed or distorted characters. STNs learn to correct these transformations, making recognition easier.
End-to-End Learning: STNs are fully differentiable and can be trained with the rest of the model.
Better Accuracy: By focusing on the relevant character regions, STNs reduce background noise and improve accuracy.
How It Works :
Localization Network: Learns transformation parameters (e.g., affine).
Grid Generator: Creates a sampling grid from parameters.
Sampler: Applies the grid to the input feature map to obtain a normalized output.
Architecture Integration (In CAPTCHA Model):
[Input Image]
↓
[STN Module (Affine Transform)]
↓
[Convolutional Layers]
↓
[Recurrent Layers (BiLSTM/GRU)]
↓
[CTC Loss or Classification]
VAE Experiment
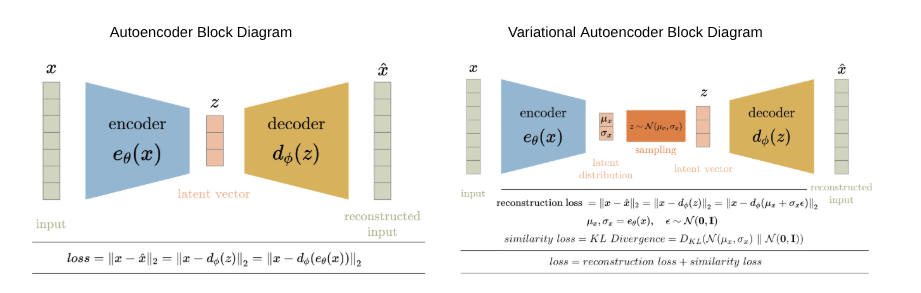
Our Captcha deciphering model has used autoencoders as the main aspect of the fusion filter network . But in general , standard autoencoders often produce latent spaces that are uninformative and lead to blurry or distorted reconstructions. VAEs introduce a probabilistic approach, mapping the input to a distribution of latent representations rather than a single point, allowing for more flexible and potentially more informative latent spaces.
On experimenting though , we found that the VAE was outperformed by the standard autoencoder. The VAE trades off reconstruction accuracy to ensure a well-structured latent space. This trade-off can degrade the sharpness or fidelity of the reconstructions. The sampling step in VAEs can introduce noise and blur. On a simple Captcha dataset with very minimal noise , this could lead to decreasing the accuracy. While VAEs aim to learn a probabilistic distribution in the latent space, autoencoders map input directly to a fixed-size vector. This deterministic approach can lead to better reconstruction accuracy
Extension
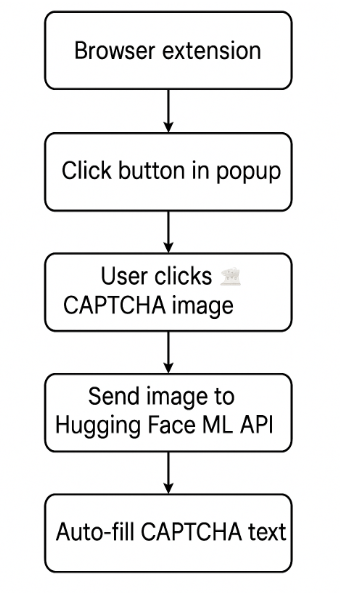
Extension Framework
The browser extension is built using HTML, JavaScript, and Chrome Manifest V3, ensuring compatibility, performance, and secure permission handling.
Trigger Mechanism
A button in the popup triggers a content script that waits for the user to click on a CAPTCHA image, activating the solve sequence.
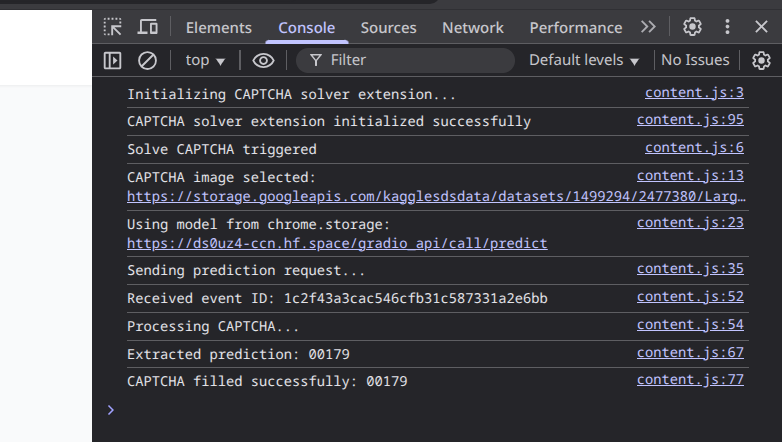
Image Capture & API Communication
On image click, the extension captures the image URL and sends it via a POST request to a Hugging Face ML model for text prediction.
Prediction Retrieval
After a brief delay, the extension fetches the prediction result using the event ID and extracts the predicted text from the API response.
Auto-fill Functionality
The extension identifies the CAPTCHA input field and inserts the predicted text, improving accessibility and streamlining the user experience.
Results:
The models were tried on a variety of data with accuracy ranging between 80% to 98%. We see that it can reliably decipher captchas with different levels and types of noise.
The introduction of spatial transformer networks shows a positive improvement to the accuracy by improving the capacity of the model to handle geometric distortions of rotation, scaling etc.
The modification of AFFN to a VAE-like architecture shows a drop in the accuracy despite the VAE having better denoising capabilities. We assume this is because of the relatively less amount of noise in the data and the error due to reconstruction,
Conclusion:
The models build show excellent accuracy on all the various dataset experimented on. The extension allows users to easily put the model to use for practical purposes. Looking ahead, future improvements to the model can be done in extending its capability to handle captcha samples dissimilar to the ones trained on and improve its ability to generalize.
References:
https://github.com/falconakhil/CaptchaCrackNet
https://github.com/dineshmanideep/captcha_cracknet
https://captchacracknetenvision25.vercel.app/
Mentors :
Akhil Sakthieswaran
Paluvadi Dinesh Manideep
Mentees :
Tanay Nahta
Abhyuday Hegde
Tapan kumar pallati
Chhitanshu Shekhar
Vivin Dsouza
Affan Arshad
Report Information
Team Members
Team Members
Report Details
Created: May 22, 2025, 10:19 a.m.
Approved by: Aakarsh Bansal [CompSoc]
Approval date: May 25, 2025, 11:58 a.m.
Report Details
Created: May 22, 2025, 10:19 a.m.
Approved by: Aakarsh Bansal [CompSoc]
Approval date: May 25, 2025, 11:58 a.m.