

Pixel Flow
Abstract
Abstract
PIXEL FLOW
AIM
To implement a Deep Convolutional Generative Adversarial Network (DCGAN) capable of generating realistic anime-style faces from a noise distribution, thereby exploring the applications of generative models in artistic and creative domains.
INTRODUCTION
In recent years, Generative Adversarial Networks (GANs) have emerged as powerful tools in generative modeling. DCGANs have demonstrated excellent performance in image synthesis tasks, particularly for datasets with strong spatial hierarchies like human or anime faces. Pixelflow is a project that leverages the DCGAN architecture to generate high-quality anime faces. By training on a curated anime dataset, the model learns to produce new, unique images that mimic the style and structure of the original data. This project contributes to AI-assisted digital art and provides a foundation for further development in AI-generated content.
TECHNOLOGIES USED
- Programming Language: Python
- Libraries: PyTorch, Streamlit, Github
- Tools: NumPy, Matplotlib, PIL
- Dataset: Anime Face Dataset
- Training Platform: Kaggle
IMPLEMENTATIONS
Shubh: GitHub
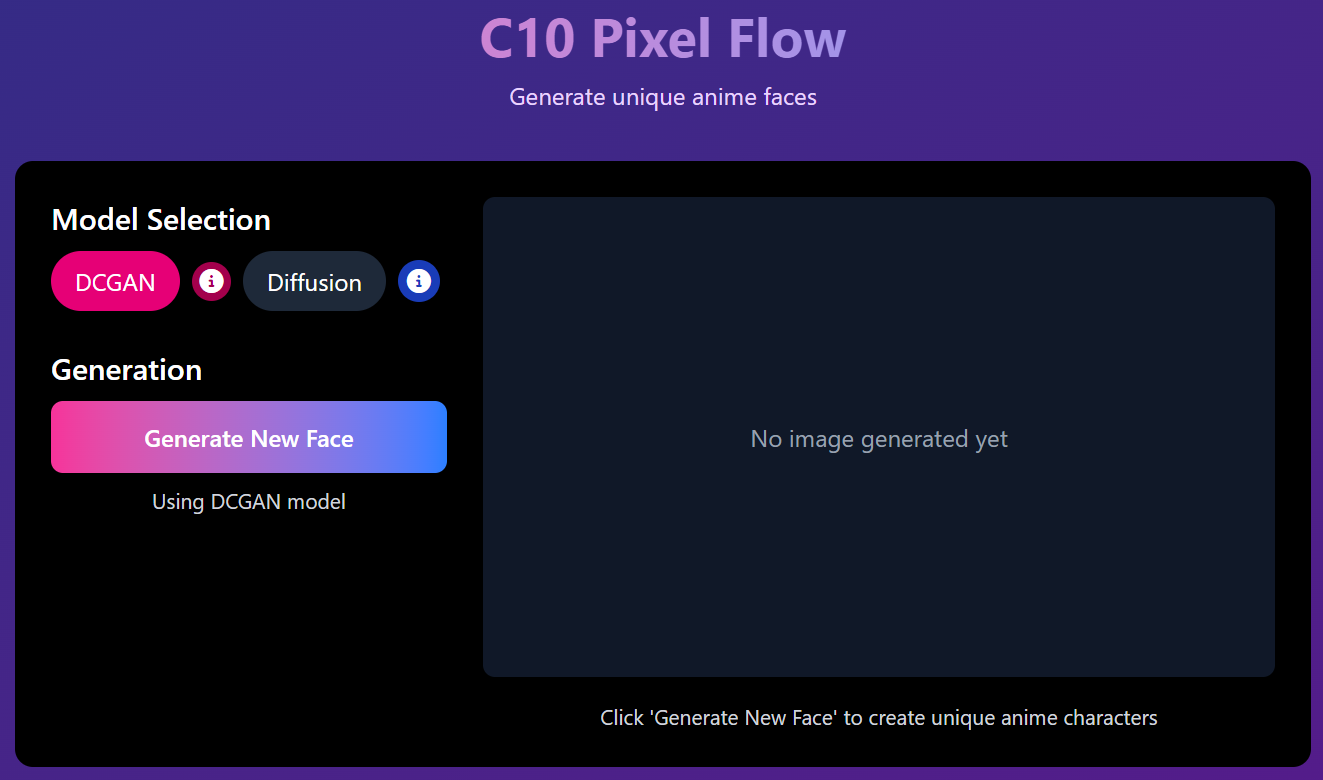

METHODOLOGY
1. Dataset Collection and Preprocessing
- The dataset comprises thousands of high-quality, aligned anime face images, sourced from publicly available repositories cited in relevant literature.
- All images are resized to a uniform resolution of 128×128 pixels to ensure architectural compatibility and efficient training.
- Pixel values are scaled to the range [-1, 1] to match the output range of the generator's Tanh activation function, improving training stability.
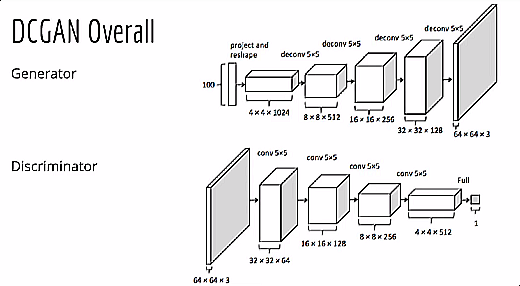
2. DCGAN Architecture
This work is primarily based on the Deep Convolutional Generative Adversarial Network (DCGAN) framework as proposed by Radford et al. (2015).
Generator:
- Input: 256-dimensional noise vector (z) sampled from a standard normal distribution.
- Architecture: A series of transposed convolutional layers, each followed by Batch Normalization and ReLU activations.
- Output: A synthesized 128×128×3 RGB image generated using a final Tanh activation layer.
Discriminator:
- Input: Real or generated 128×128×3 RGB image.
- Architecture: Convolutional layers with Batch Normalization and LeakyReLU activations to stabilize gradients.
- Output: A single scalar value between 0 and 1 via a Sigmoid activation, indicating the probability of the image being real.
3. Training Procedure
- Loss Functions:
- Generator: Binary Cross-Entropy Loss against the discriminator's prediction
- Discriminator: BCE loss distinguishing real from fake images
- Optimizer: Adam (β1 = 0.5, β2 = 0.999)
- Training Duration: 100+ epochs
- Monitoring:
- Progress tracked using image grids and loss curves at regular intervals
- Generator Loss: stabilized around 2.99–3.05
- Discriminator Loss: stabilized around 0.52–0.53
4. Additional Experiments
Self-Attention GANs
- Experimented with Self-Attention GAN (Zhang et al., 2019) to enhance the capture of long-range dependencies in the generated images. While the self-attention mechanism improved the global structures, the overall improvement in image quality was not significant. So, results from the self-attention setup were not here.
Diffusion Model
- Implemented a Denoising Diffusion Probabilistic Model (DDPM) (Ho et al., 2020) as an alternative generative approach.
- Architecture:
-
U-Net with time-conditioned residual blocks (ResBlock) and self-attention(FlashAttention) layers.
-
Sinusoidal time embeddings for timestep conditioning.
-
Processes 128x128x3 RGB images.
-
- Noise Schedule: Cosine beta schedule for stable training.
- Training Enhancements:
-
Exponential Moving Average (EMA): Decay rate of 0.9999 for smoother parameter updates.
-
Perceptual Loss: Used a pre-trained VGG network for timesteps ≤ 500 to enhance visual quality.
-
Mixed Precision Training: Leveraged torch.autocast (bfloat16) for efficiency on CUDA.
-
Gradient Clipping: Applied to prevent exploding gradients.
-
torch.compile: Applied to prevent exploding gradients.
-
- Sampling: DDIM-inspired sampling with 100 steps (eta = 0.3) to generate high-quality images.
- Challenges: Longer training times due to iterative denoising. However, optimizations reduced training time from 1.5 hours per epoch to 15-16 minutes per epoch.
- Results: Improved sample quality significantly, but higher computational cost than DCGAN.
- Generated images:

RESULTS
- DCGAN: Generated diverse, high-fidelity 128x128 anime faces with distinct features (e.g., eyes, hair, colors).
-
Training Stability: Discriminator loss stabilized early, with generator loss improving steadily.
-
Visual Quality: Generated images closely resemble the training dataset, validated through visual comparisons.
-
Diffusion Model: Higher quality but computationally intensive, suitable for specific use cases.
-
Final model capable of generating diverse and aesthetically appealing anime faces from random noise.
CONCLUSIONS / FUTURE SCOPE
Conclusions
Pixelflow successfully demonstrates the potential of DCGANs in generating anime-style faces with high visual quality. The adversarial training framework proves effective for creative applications, even with relatively shallow architectures and limited datasets. The results validate that minimal preprocessing and simple training pipelines can yield significant generative quality.
Future Scope
- Resolution Enhancement: Incorporating models like Progressive GAN or StyleGAN for higher resolution outputs.
- Conditional GANs: Add label control to generate faces with specific attributes (e.g., hair color, expression).
- Animation Generation: Extend to full-body character generation or frame-by-frame anime animation.
REFERENCES
- Radford, A., et al. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.
- Zhang, H., et al. (2019). Self-Attention Generative Adversarial Networks.
- Ho, J., et al. (2020). Denoising Diffusion Probabilistic Models.
- Learning references: Python Pytorch Hands On Pytorch Statquest Git ML Resource 1 ML Resource 2 Linear Algebra
- Reference GitHub Repository
- Envision Learning Tasks
MENTORS
- Vishruth V Srivatsa
- Swaraj Singh
MENTEES
- Aryan Palimkar
- Deepthi K
- Devansh Sharma
- Vanja Rohan
- Rohith P
- Shubh Thakkar
Report Information
Team Members
Team Members
Report Details
Created: May 22, 2025, 10:47 p.m.
Approved by: Raajan Rajesh Wankhade [CompSoc]
Approval date: May 25, 2025, 12:29 a.m.
Report Details
Created: May 22, 2025, 10:47 p.m.
Approved by: Raajan Rajesh Wankhade [CompSoc]
Approval date: May 25, 2025, 12:29 a.m.