

NoiseNil
Abstract
Abstract
Noise Nil
Google meet Link: Envision Project Expo LInk
Introduction:
Audio recordings are often affected by background noise due to environmental conditions, hardware limitations, or transmission errors. This degradation impacts the quality and clarity of audio, making tasks like transcription, speaker identification, and general listening more difficult. Traditional signal processing methods offer limited effectiveness.
Our goal is to improve audio quality by effectively removing noise while preserving the clarity and structure of the original speech.
Aim:
The project builds a deep learning-based denoising model that takes the spectrogram of a noisy audio signal and predicts a cleaner version. Our approach uses a U-Net architecture with a resnet backbone, and a convolutional neural network (CNN) based Dn-CNN model designed to capture both local and global patterns in spectrogram images.
Technologies Used:
1. Python
2. Libraries used: numpy, pandas, librosa, tensorflow, etc.
3. The model is trained using GPU T4x2 on Kaggle
4. Dataset contains audio samples of speech, clean and noisy audios being paird (both train and test directories)
Literature Survey:
1. Classical Audio Denoising Techniques
Traditional approaches to speech enhancement include spectral subtraction, Wiener filtering, and statistical model-based filtering. These methods often assume stationary noise and linear signal characteristics.
Spectral Subtraction: Subtracts an estimated noise spectrum from the noisy signal. Often introduces "musical noise."
Reference: Boll, S. F. (1979). "Suppression of acoustic noise in speech using spectral subtraction." IEEE Transactions on Acoustics, Speech, and Signal Processing, 27(2), 113-120.
Wiener Filtering: Minimizes the mean square error between the estimated and clean signal.
Reference: Lim, J. S., & Oppenheim, A. V. (1979). "Enhancement and bandwidth compression of noisy speech." Proceedings of the IEEE, 67(12), 1586–1604.
These techniques struggle in real-world noisy conditions, motivating the shift to data-driven methods.
2. Deep Learning Approaches for Speech Enhancement
2.1 Deep Neural Networks (DNNs) and Recurrent Networks
Initial deep learning models used feedforward DNNs or recurrent architectures like LSTM for mapping noisy to clean features.
Reference: Xu, Y., Du, J., Dai, L.-R., & Lee, C.-H. (2014). "An experimental study on speech enhancement based on deep neural networks." IEEE Signal Processing Letters, 21(1), 65–68.
Reference: Weninger, F., Erdogan, H., Watanabe, S., Vincent, E., Le Roux, J., Hershey, J. R., & Schuller, B. (2015). "Speech Enhancement with LSTM Recurrent Neural Networks." INTERSPEECH.
3. CNN-Based Denoising Models
3.1 DnCNN (Denoising Convolutional Neural Network)
Originally developed for image denoising, DnCNN has been effectively adapted to spectrogram and waveform denoising tasks.
Learns residual noise instead of clean signal, improving convergence and quality.
Can generalize across different noise levels and types.
Reference: Zhang, K., Zuo, W., Chen, Y., Meng, D., & Zhang, L. (2017). "Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising." IEEE Transactions on Image Processing, 26(7), 3142-3155.
Adaptation for audio:
Reference: Xu, Y., Du, J., Dai, L. R., & Lee, C. H. (2015). "A regression approach to speech enhancement based on deep neural networks." IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(1), 7–19.
4. ResNet-Enhanced U-Net
Combining U-Net with ResNet backbones enhances feature extraction by incorporating residual blocks that enable better gradient flow and deeper representations.
ResNet mitigates vanishing gradients and helps deeper networks learn effectively.
Using ResNet as a backbone for U-Net improves its ability to capture both local (low-level) and global (high-level) spectro-temporal features.
Reference: He, K., Zhang, X., Ren, S., & Sun, J. (2016). "Deep Residual Learning for Image Recognition." CVPR.
Audio application: Kong, Q., Cao, Y., Iqbal, T., Wang, Y., Wang, W., & Plumbley, M. D. (2020). "PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition." IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 2880–2894.
METHODOLOGY:
Data Preparation:
The audio Denoising dataset, paired clean and noisy audio data is used to train model. Dataset also contains transcript of the audio; it is divided to train and test the model.
Additionally, data augmentation is performed on the audio samples to increase the amount of input data to the model. The methods used for the same are:
1. Adding artificial noise
2. Applying reverb
3. Clipping
4. Applying a lowpass filter for muffled sound
5. Shifting audio
6. Volume scaling
Spectrogram Processing:
Spectrograms or audio images of the audio samples are made applying stft on the audio samples. Spectrograms are treated as images (2D representations of audio signals). Spectrograms are made with linear-magnitude using librosa.stft (STFT Short-Term Fourier Transform).
We extract image square patches from noisy and clean spectrograms for training.
Patches help the model focus on local time-frequency patterns and reduce memory usage.
Architecture of CNN used:
Two approaches were tired and tested to get the final denoised result:
DnCNN architecture based model
The model implemented is a variant of the Denoising Convolutional Neural Network (DnCNN), enhanced with regularization and tunable hyperparameters to improve denoising performance on spectrogram inputs. This architecture is designed to learn the mapping between noisy and clean spectrogram representations of audio signals, using residual learning principles and modern deep learning techniques.
Input Layer
The network begins with an input layer designed to accept 2D spectrograms (e.g., magnitude spectrograms derived from STFT). These inputs retain the time-frequency structure of the audio, which is essential for effective noise suppression while preserving speech clarity.
Feature Extraction Block
The first layer of the network is a convolutional layer with a small kernel, applied to capture local features from the noisy input. This layer is followed by a non-linear activation function (ReLU), which introduces non-linearity and allows the model to learn more complex representations.
Denoising Core (Middle Convolutional Stack)
A sequence of intermediate convolutional layers is employed, each followed by batch normalization and activation layers. These layers enable the network to refine its understanding of the underlying clean signal and noise characteristics. Batch normalization stabilizes and accelerates training by normalizing activations, while dropout regularization is used to prevent overfitting by randomly deactivating a fraction of the neurons during training. The depth and width of this block are dynamically tunable, allowing the model to adapt in complexity depending on the training scenario and dataset.
Output Layer
The final convolutional layer produces a single-channel output, representing the predicted clean spectrogram. Unlike traditional approaches that directly predict the clean signal, this model learns a mapping that can also serve for residual noise suppression. While residual subtraction is commented out in this implementation, the structure is compatible with residual learning strategies, where the noise estimate is subtracted from the noisy input to yield a denoised signal.
Loss and Optimization
The model uses the log-cosh loss function, which is less sensitive to outliers than mean squared error and helps produce more perceptually convincing outputs. For evaluation, a custom Signal-to-Noise Ratio (SNR) metric is used, which quantifies the improvement in audio quality after denoising. The model is optimized using the Adam optimizer, and both learning rate and regularization strengths are tunable through hyperparameter optimization.
Hyperparameter Tuning Integration
This architecture is implemented as a HyperModel compatible with Keras Tuner, enabling automated hyperparameter optimization. Parameters such as the number of filters, dropout rates, regularization strengths, depth of the network, and learning rate can be adjusted to identify the optimal configuration for a given dataset or task.
ResNet architecture based model
The model constructed is a deep learning-based image denoiser that leverages the powerful U-Net architecture combined with a ResNet101 backbone pretrained on ImageNet. This combination is designed to effectively remove noise from input spectrogram images (or grayscale images) while preserving fine details.
Key Architectural Components
1. Input Handling
The model accepts a single-channel input, such as a grayscale spectrogram patch. Because the backbone network (ResNet101) is pretrained on RGB images (which have three channels), the model first converts the single-channel input into a three-channel format. This is achieved through a simple 1x1 convolutional layer that replicates and projects the input into a form compatible with the backbone.
2. Encoder Backbone: ResNet101
At the heart of the model lies the ResNet101 encoder, a deep residual network pretrained on large-scale natural images. This backbone is responsible for extracting hierarchical, multi-scale feature representations from the input. Its residual blocks allow the network to learn complex features efficiently while mitigating issues such as vanishing gradients during training.
The encoder progressively compresses the spatial information while enriching the feature depth, capturing both low-level textures and high-level semantic cues that are critical for accurate noise identification and removal.
3. U-Net Structure
The model follows the U-Net paradigm, which is particularly effective for image-to-image tasks like denoising. The U-Net architecture consists of two parts:
Encoder path: The pretrained ResNet101 serves as the encoder that compresses the input image into a rich set of features.
Decoder path: Corresponding to the encoder, the decoder upsamples these features back to the original resolution. Skip connections between encoder and decoder layers enable the model to combine low-level spatial details with high-level abstract features, which is essential for preserving fine-grained image details during reconstruction.
These skip connections are critical because they help the model recover spatial details lost during downsampling, leading to sharper and more faithful denoised outputs.
4. Output Layer
After passing through the decoder, the model outputs a multi-channel feature map that is then transformed back to a single-channel denoised image using a final 1x1 convolutional layer with a sigmoid activation function. This ensures that the output is in the same format as the input (grayscale) and that pixel values are constrained within a normalized range, suitable for representing clean spectrogram intensities or image brightness.
Training:
Loss Function used is log_loss and metric SNR, is used between predicted and ground-truth clean spectrograms along with Adam optimizer.
The CNN model takes a noisy spectrogram patch as input and predicts a clean spectrogram patch.
Reconstruction:
Predicted spectrogram output is converted back to time-domain audio using Inverse STFT. The phase from noisy spectrogram is used during reconstruction.
Future enhancements:
The following future enhancements can be made for the model:
1. Use of transformer based models for better noise removal
2. Currently, the model is using only the magnitude spectrogram. Audio quality can be improved by modelling phase information along with magnitude.
3. Combining denoising with other tasks such as speech enhancement, etc
4. Include hyperparameter tuning in the code (for now, due to computational complexities, it wasn’t included)
Model Evaluation and Performance:
Using the Dn-CNN approach, the least possible MSE achieved is 0.0039 and the SSIM with the spectrorams is about 0.0788.
Scope for improvement persists, but methodology was executed correctly and according to the pipeline. This method, in addition to pre processing, hyperparameter tuning and post processing, performs better than the u-net model with resnet backbone
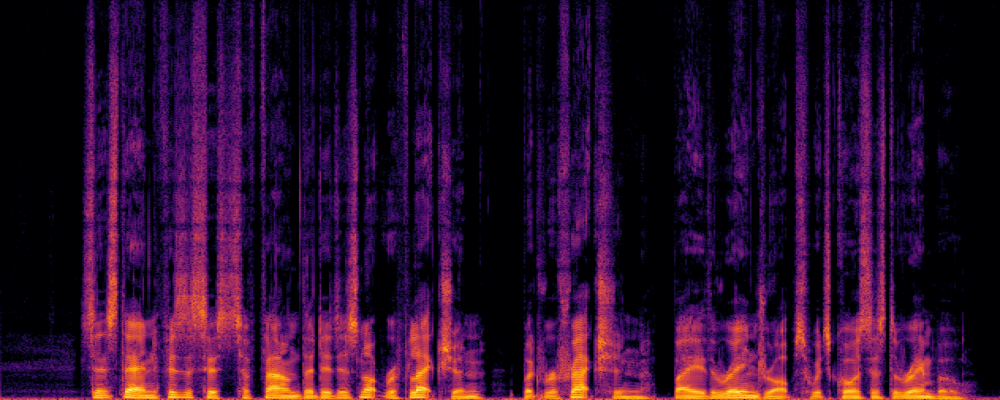
Example spectrogram (grayscale) taken for testing (clean version)
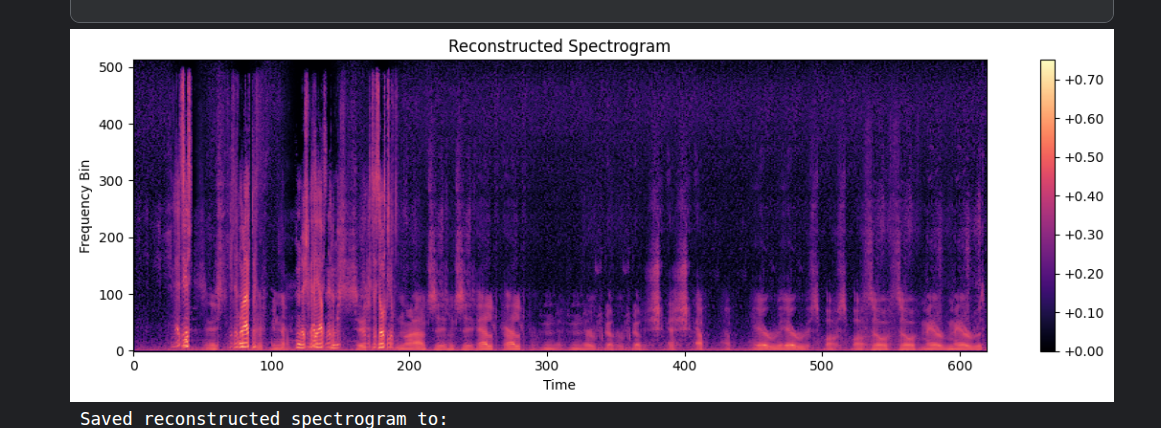
Reconstructed spectrogram (before post processing)
References :
Mentors:
Shruti Hegde
Dammu Chaitanya
Mentees:
Pratham Adithya
Sreevas S
Tarun
Harsh Vardhan Bagri
Vedang Paranjape
Report Information
Team Members
Team Members
Report Details
Created: May 23, 2025, 1:58 a.m.
Approved by: Vaibhav Santhosh [Diode]
Approval date: May 25, 2025, 4:35 p.m.
Report Details
Created: May 23, 2025, 1:58 a.m.
Approved by: Vaibhav Santhosh [Diode]
Approval date: May 25, 2025, 4:35 p.m.