

EmotionScope: Multimodal Emotion Recognition in Conversation
Abstract
Abstract
Google Meet Link: https://meet.google.com/zsq-yoim-omr
Github Repository: https://github.com/Vanshika-Mittal/EmotionScope
Aim
To develop a multimodal emotion recognition system using the MELD dataset by integrating textual and visual inputs through a late fusion architecture, performing emotion classification in conversational settings.
Introduction
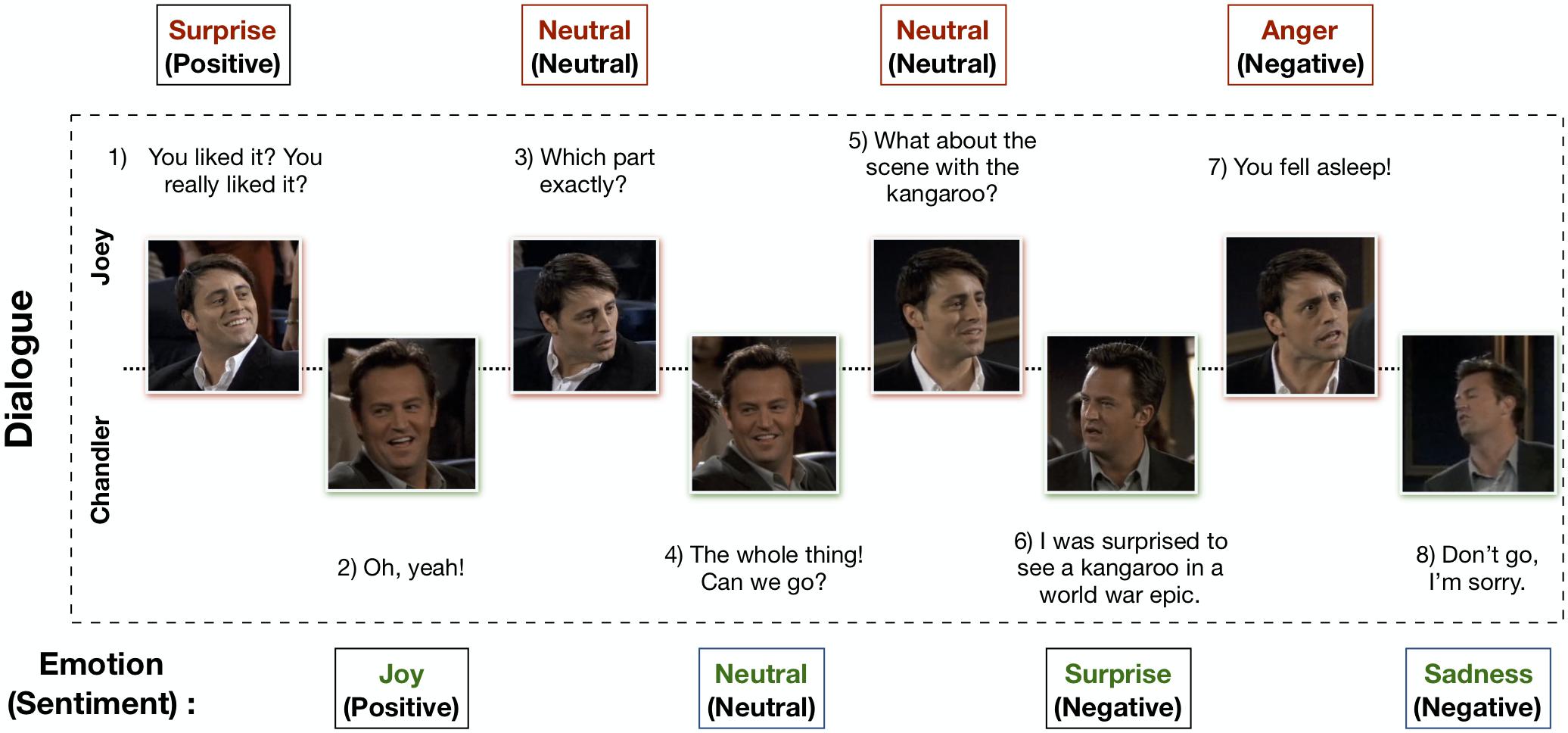
Emotions are key to effective communication, influencing interactions and decision-making. This project aims to bridge the gap between humans and machines by recognizing emotions in conversations using both text and facial expressions. Leveraging the MELD dataset, we implement two parallel modules:
- a TF-IDF-based NLP model for dialogue processing
- a ResNet-18-based vision model for facial expression analysis.
- By combining these through a late fusion strategy, our system achieves more accurate emotion detection.
This system has applications in areas like customer support, mental health monitoring, and human-computer interaction.
Literature survey and technologies used
Papers referred to:
- Paper Link: https://arxiv.org/pdf/1810.02508.pdf
- Dataset Link: https://affective-meld.github.io/ (MELDA)
- An Assessment of In-the-Wild Datasets for Multimodal Emotion Recognition
Methodology
Textual Feature Extraction
In our project, we utilize the TF-IDF (Term Frequency-Inverse Document Frequency) representation in combination with Logistic Regression to classify the emotional content of dialogue utterances in the MELD dataset.
TF-IDF is a numerical statistic that reflects how important a word is to a document in a collection (or corpus). It balances two components:
- Term Frequency (TF): Measures how frequently a term appears in a document. A higher frequency indicates greater importance.
- Inverse Document Frequency (IDF): Measures how unique or rare a term is across all documents. Rare terms across the corpus receive higher weights.
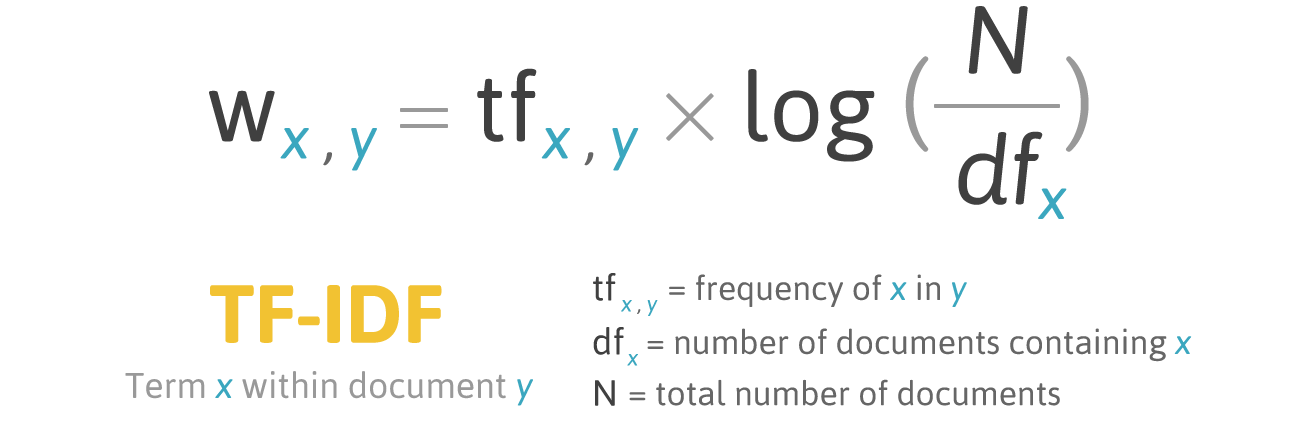
Logistic Regression is a linear classifier that we used to model the probability that a given input belongs to a particular class using the softmax function. During training, the model then optimizes a cross-entropy loss to maximize the predicted probability of the correct label.
Visual Feature Extraction from Images
The presence of images alongside text helps in capturing subtle emotional cues more effectively during emotion analysis. To make use of this, we extracted keyframes from videos present in the MELD dataset — selecting frames where different individuals displayed distinct emotions. These facial images were then mapped to the corresponding utterances and labelled emotions from the textual dataset.
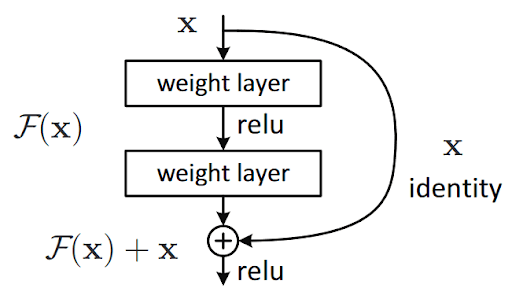
To extract meaningful visual features from each face, we used a Residual Neural Network (ResNet-18). This architecture is composed of stacked 3×3 convolutional layers, each followed by batch normalization and ReLU activation. Towards the end, an adaptive average pooling layer reduces the spatial dimensions of the feature maps to a fixed size, enabling consistent output regardless of input image size. The key innovation in ResNets is the skip (residual) connections, which allow gradients to flow directly through earlier layers. This helps solve the vanishing gradient problem and makes it easier for the network to learn identity mappings when needed — enabling more effective and deeper feature extraction.
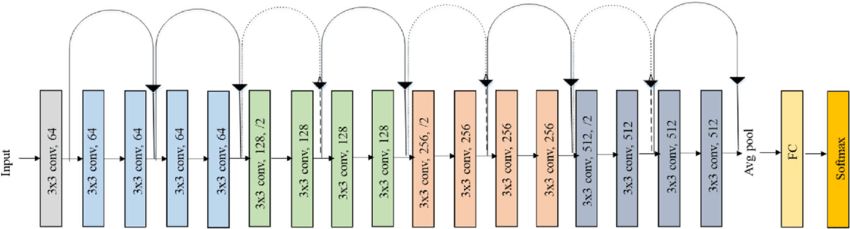
Since our task involved predicting 7 emotion classes (instead of the 1000 classes used in ImageNet), we removed the final fully connected (classification) layer of ResNet-18. This allowed us to:
- Fuse the extracted visual features with text features from other modalities
- Customize the output to match the 7 unique emotion categories relevant to our dataset
Multimodal Fusion
Our emotion recognition model employs late fusion to integrate insights from textual and visual data using the MELD dataset. Text features are extracted using TF-IDF, followed by classification through Logistic Regression, capturing linguistic indicators of emotion. Visual cues, such as facial expressions, are processed using a ResNet architecture, which effectively extracts deep spatial features from images.
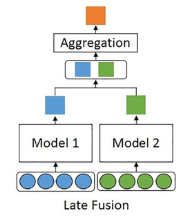
We chose late fusion as our fusion strategy because it allows each modality to be modeled independently using the most suitable architecture. This separation ensures that the strengths of each modality are preserved without interference during feature learning.
Late fusion offers several advantages:
- It is modular, easy to interpret, and robust to missing or noisy data in one modality.
- It avoids the complexity and training challenges associated with early or intermediate fusion, making it ideal for scenarios with heterogeneous features.
By using this approach, our system effectively captures complementary emotional signals from both language and facial expressions, leading to more accurate and reliable emotion recognition.
Results
To evaluate the performance of our emotion recognition system, we conducted experiments across three setups:
1. Text-only classification using TF-IDF + Logistic Regression
The TF-IDF-based model performed reasonably well on shorter utterances and common emotion categories. However, it struggled with context-dependent emotions such as sarcasm.
2. Image-only classification using ResNet-18
Using ResNet-18 for facial expression classification offered moderate performance. The model was sensitive to facial visibility, lighting, and resolution—limitations inherent to static frame analysis. We achieved ~42% accuracy.
3. Multimodal classification using a late fusion of both models
By combining predictions from both modalities using a late fusion strategy, we observed a significant boost in classification performance. We achieved ~45% accuracy.
Conclusions/Future Scope
This project demonstrates the effectiveness of a multimodal approach for emotion recognition in conversations using the MELD dataset. By combining a TF-IDF + Logistic Regression model for text with a CNN-based model for facial expression analysis, we show that integrating multiple modalities improves classification performance compared to single-modality systems.
Future Scope:
- Advanced NLP Models: Incorporating models like LSTM, GRU, or BERT can capture temporal dependencies and contextual nuances across utterances, leading to better emotion classification performance.
- Early/Mid Fusion Architectures: Exploring fusion strategies beyond late fusion—such as early or hybrid fusion—may enable richer interactions between text and visual features, improving emotional understanding.
- Multimodal Context Modeling: Using conversational context (previous utterances, speaker history) and adding audio features (tone, pitch) can make the system more robust.
Project By:
Mentors
- Vanshika Mittal
- Rakshith Ashok Kumar
Mentees
- Pradyun Diwakar
- Shriya Bharadwaj
- Vashisth Patel
- Deepthi Komar
- Karthikeya Gupta
- Kowndinya Vasudev
Report Information
Team Members
Team Members
Report Details
Created: May 23, 2025, 10:10 a.m.
Approved by: Raajan Rajesh Wankhade [CompSoc]
Approval date: May 25, 2025, 12:13 a.m.
Report Details
Created: May 23, 2025, 10:10 a.m.
Approved by: Raajan Rajesh Wankhade [CompSoc]
Approval date: May 25, 2025, 12:13 a.m.