

Transcripto
Abstract
Abstract
Introduction
Automatic Speech Recognition (ASR) refers to the process of converting spoken language into written text. It is a fundamental task in speech processing with applications in virtual assistants, transcription services, and accessibility tools. In recent years, deep learning has significantly advanced the capabilities of ASR systems. This project investigates two approaches for building speech recognition systems using deep learning: the first involves traditional sequence modeling using Long Short-Term Memory (LSTM) networks, and the second leverages Wav2Vec 2.0, a Transformer-based model that has set new benchmarks in self-supervised speech representation learning.
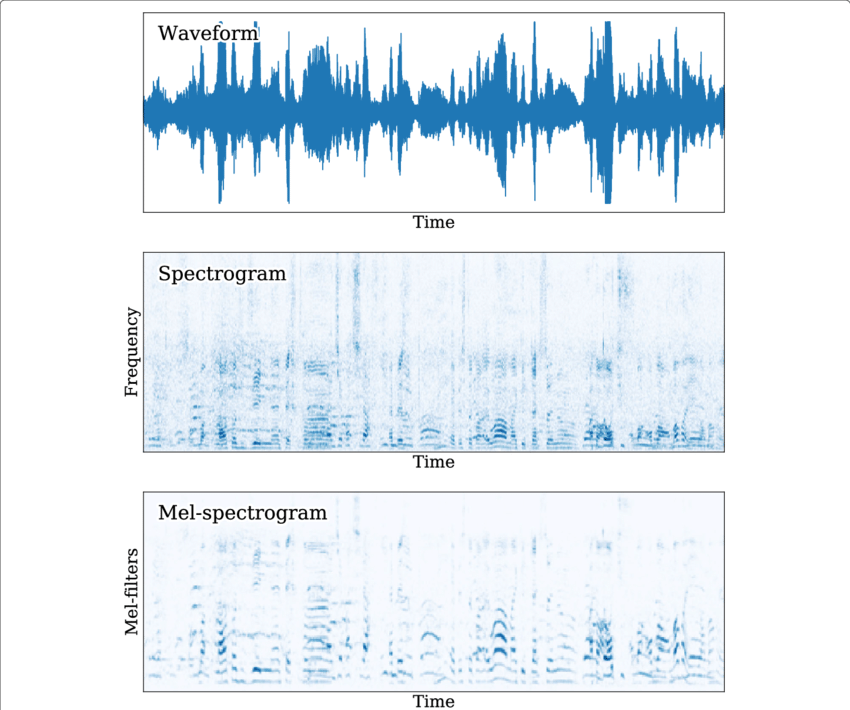
Frequency Feature Extraction
When working with audio signals in machine learning and signal processing, it is often beneficial to analyze them in the frequency domain rather than the time domain.
Why Use Frequency Domain Features?
- Better representation of human perception: The human ear is more sensitive to certain frequencies. Frequency-domain features can capture perceptual aspects of sound more effectively.
- Noise robustness: Frequency representations often make it easier to filter out noise or irrelevant components.
What is a Mel-Spectrogram?
A mel spectrogram is a time-frequency representation of sound that maps the audio signal to the mel scale, which is a perceptual scale of pitches judged by listeners to be equal in distance from one another.
- Divide the waveform into overlapping frames and compute the Short-Time Fourier Transform (STFT) to get the frequency components over time.
- Apply Mel Filter Bank: Use a set of triangular filters spaced according to the mel scale to map the FFT output to mel frequencies.
- Apply a logarithm to the mel spectrogram to compress the dynamic range and approximate how humans perceive loudness.
RNNs and LSTMs
Recurrent Neural Network (RNN)
Recurrent Neural Networks are a type of neural network designed to model sequential data by maintaining a hidden state that evolves over time. At each time step, an RNN processes the current input along with the hidden state from the previous time step. This allows RNNs to capture temporal dependencies in data like speech, text, or time series.
However, standard RNNs suffer from the vanishing and exploding gradient problems when dealing with long sequences. As a result, they struggle to retain information over extended time periods, which limits their effectiveness for tasks like ASR that depend on long-range context.
Long Short-Term Memory (LSTM)
LSTMs are a special type of RNN that addresses these limitations using memory cells and three types of gates:
- Forget gate: Determines what information should be discarded from the cell state.
- Input gate: Decides what new information should be stored in the cell state.
- Output gate: Controls the output based on the cell state.
This gating mechanism allows LSTMs to retain information over long time spans, making them well-suited for modeling the sequential and temporal structure of speech.
Transformers
Transformers are deep learning architectures that rely entirely on self-attention mechanisms rather than recurrence. Self-attention allows the model to weigh the importance of different positions in the sequence when encoding a particular input, making it possible to capture long-range dependencies more effectively than RNNs.
Transformers also support parallel processing of input sequences, resulting in faster training and inference times. Originally developed for natural language processing, they have been successfully applied to speech tasks, including ASR, due to their scalability and representational power.
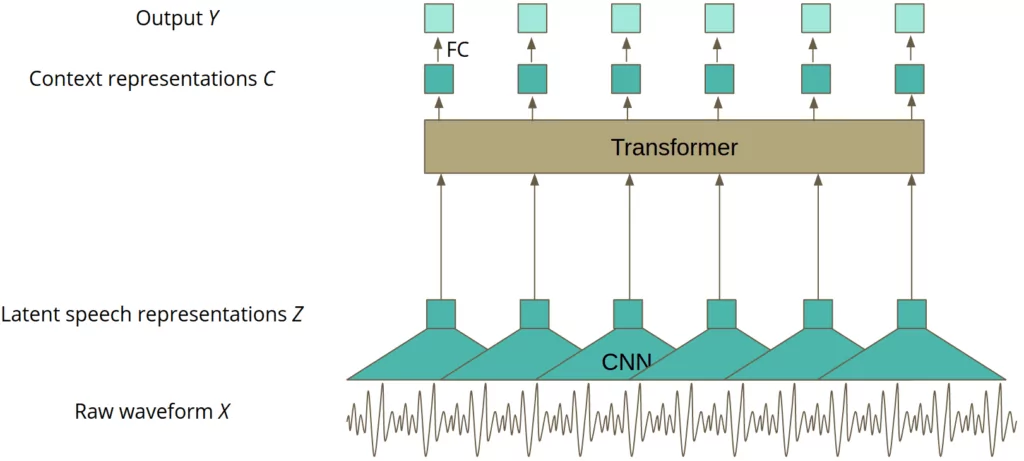
Wav2Vec 2.0
Wav2Vec 2.0 is a Transformer-based model developed by Facebook AI for self-supervised learning of speech representations. It processes raw audio waveforms and learns context-rich embeddings through two stages:
- Feature Encoder: A convolutional network that extracts latent speech representations from raw audio.
- Context Network: A Transformer that models dependencies across time steps and produces contextualized representations.
The model is pre-trained on large amounts of unlabeled audio data by solving a contrastive task, and then fine-tuned on labeled data using a CTC loss. This approach enables the model to generalize well and perform strongly even with limited supervision.
Methodology
Approach 1: RNN and LSTM-based Speech-Command Recognition
The first approach focuses on classifying short, fixed-length spoken commands using deep learning. The dataset used is the Speech Commands Dataset, which contains 1-second audio clips representing 10 distinct spoken commands such as “yes,” “no,” and “stop.”
Dataset Details:
- Training samples: ~85,000
- Validation samples: ~10,000
- Each sample is a 1-second mono audio clip.
Feature Extraction:
- Extracted 40-dimensional Mel-Frequency Cepstral Coefficients (MFCCs)
- Parameters: 1024-point FFT window, hop length of 500 samples
- 64 Mel filterbanks used
- Inputs were zero-padded or truncated to a fixed length of 32 frames.
- Feature normalization was performed using statistics computed over the training set (mean and standard deviation).
Two neural network architectures were evaluated:
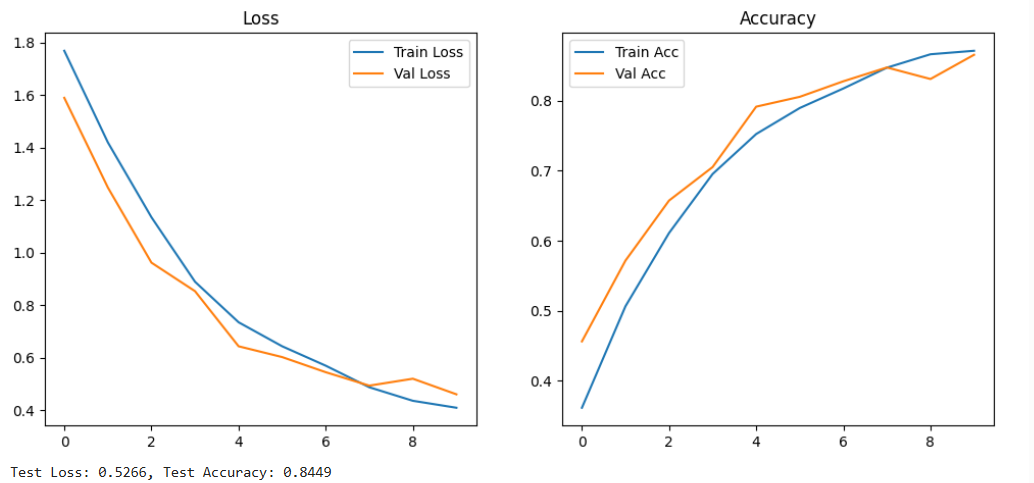
RNN Architecture:
- 2-layer RNN
- 512 hidden units per layer
- No dropout applied
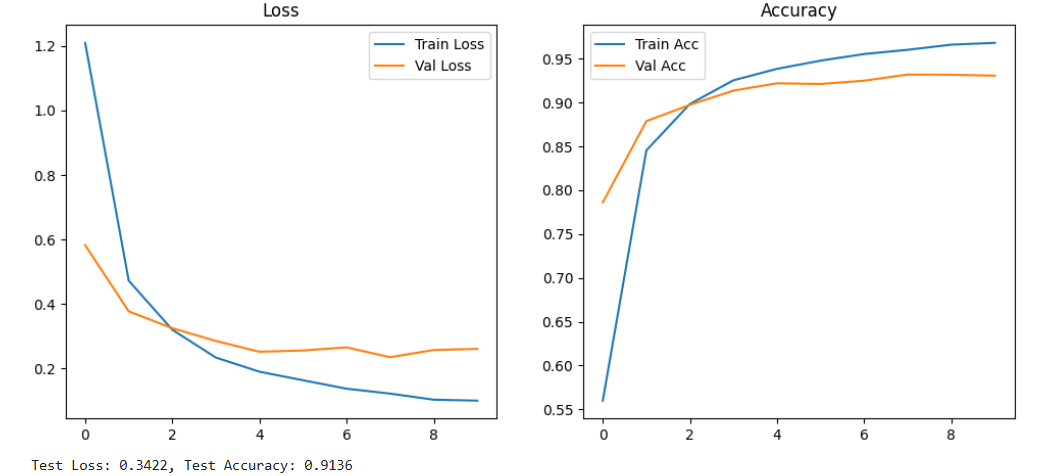
LSTM Architecture:
- 2-layer bidirectional LSTM
- 128 hidden units per direction (256 total per layer)
- Dropout rate: 0.5
Approach 2: LSTM-Based Automatic Speech Recognition (ASR)
This approach targets end-to-end speech transcription using a bidirectional LSTM model trained on the LibriSpeech train-clean-100 subset, which comprises approximately 100 hours of read English speech. The objective is to convert raw audio into text without requiring time-aligned labels, made possible by training with Connectionist Temporal Classification (CTC) loss, which handles alignment implicitly.
Preprocessing:
- All audio is resampled to 16 kHz.
- Log-Mel spectrograms are extracted as input features.
- On the text side, a character-level vocabulary is constructed (including a special CTC blank token), and transcripts are encoded as sequences of character indices.
Model Architecture:
- The model consists of a 3-layer bidirectional LSTM with dropout.
Evaluation:
- The model achieves a Word Error Rate (WER) below 0.8 and a Character Error Rate (CER) between 0.15 and 0.20, indicating solid baseline performance on clean speech data.

Performance could be further improved by:
- Hyperparameter tuning
- Applying data augmentation (e.g., SpecAugment)
- Using language models during decoding
Approach 3: End-to-End ASR with Wav2Vec 2.0
The third approach addresses the full Automatic Speech Recognition (ASR) task by fine-tuning the Wav2Vec 2.0 model Fine-tuning was performed on a curated subset of the LibriSpeech train-clean-100 dataset using Connectionist Temporal Classification (CTC) loss, which enables training without explicit alignment between audio and text.
Key Components:
- Dataset: A small subset ranging from 20 to 300 samples from the train-clean-100 split of LibriSpeech was used for experimentation.
- Feature Extraction: No manual preprocessing is needed; raw audio is passed to a CNN-based encoder that learns latent representations, which are then processed by a multi-layer Transformer.
- Text Preprocessing: Transcripts are normalized by removing punctuation and converting to uppercase. Each character is then mapped to a unique ID using a custom tokenizer.
- Loss Function: CTC is employed to handle variable-length alignment between acoustic frames and character sequences, making the model robust to timing variability in speech.
Conclusion
This project demonstrates the evolution of ASR from traditional RNN-based models using handcrafted features to powerful transformer models trained end-to-end. While LSTM models are highly effective for command recognition with compact inputs, transformer-based models like Wav2Vec 2.0 are better suited for large-scale transcription tasks. Future work includes full-dataset training, improved decoding methods, and exploring multilingual and domain-specific fine-tuning.
Mentors
- Asrith Singampalli
- Guhan Balaji
Mentees
- Nithin N.
- Nirmit Pitroda
- Ojas Joshi
- M. Phanindra
Report Information
Team Members
Team Members
Report Details
Created: May 23, 2025, 11:14 p.m.
Approved by: Vaibhav Santhosh [Diode]
Approval date: May 25, 2025, 12:25 p.m.
Report Details
Created: May 23, 2025, 11:14 p.m.
Approved by: Vaibhav Santhosh [Diode]
Approval date: May 25, 2025, 12:25 p.m.